



简介
Milvus是一个于2019年创建的数据库,其目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。
作为一个专门设计用于处理输入向量查询的数据库,它能够在万亿级别上索引向量。与现有的关系型数据库主要处理按照预定义模式的结构化数据不同,Milvus从底层开始设计,处理从非结构化数据转换而来的嵌入向量。
随着互联网的发展与演进,非结构化数据变得越来越普遍,包括电子邮件、论文、物联网传感器数据、Facebook照片、蛋白质结构等等。为了使计算机能够理解和处理这些非结构化数据,需要使用嵌入技术将其转换为向量。Milvus存储并索引这些向量。Milvus能够通过计算向量之间的相似距离来分析两个向量之间的相关性。如果两个嵌入向量非常相似,意味着原始数据源也是相似的。
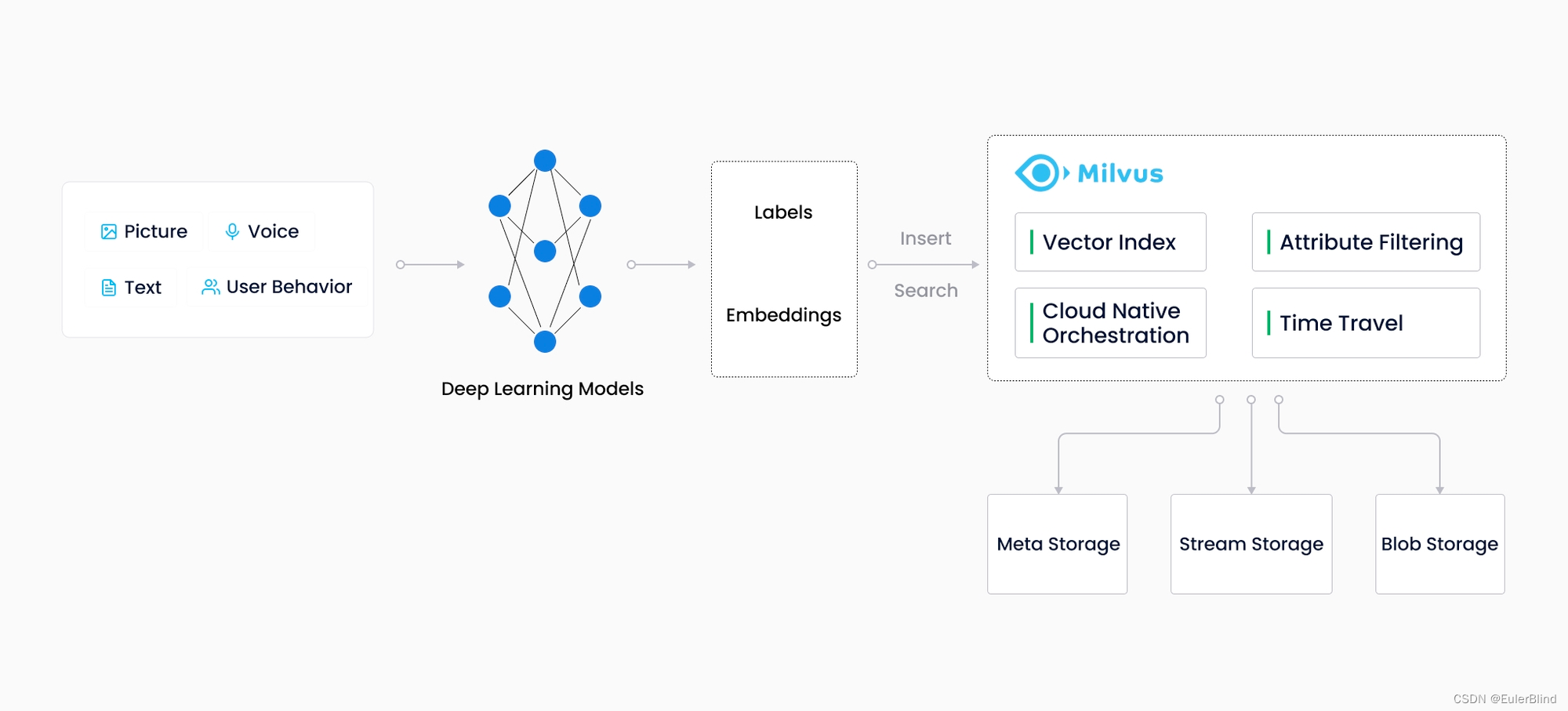
** Milvus 工作流**
关键概念
非结构化数据
非结构化数据包括图像、视频、音频和自然语言等信息,它不遵循预定义的模型或组织方式。这种数据类型占据了世界数据的约80%,可以通过各种人工智能(AI)和机器学习(ML)模型转换为向量。
Embedding 向量
embedding向量是非结构化数据的特征抽象,例如电子邮件、物联网传感器数据、Instagram照片、蛋白质结构等。从数学上来说,嵌入向量是一组浮点数或二进制数组。现代嵌入技术用于将非结构化数据转换为嵌入向量。
向量相似度搜索
向量相似度搜索是将一个向量与数据库进行比较,以找到与查询向量最相似的向量的过程。近似最近邻(ANN)搜索算法用于加速搜索过程。如果两个嵌入向量非常相似,意味着原始数据源也是相似的。
Milvus 特征
- 在处理大规模数据集上进行向量搜索时具有高性能。
- 面向开发者的社区,提供多语言支持和工具链。
- 具备云可扩展性和高可靠性,即使在出现中断的情况下也能保持稳定。
- 通过将标量过滤与向量相似度搜索相结合,实现混合搜索
支持的索引和度量方法是什么?
索引是数据的组织单位。在执行搜索或查询已插入实体之前,必须声明索引类型和相似度度量方法。如果您没有指定索引类型,Milvus将默认使用暴力搜索。
Milvus索引类型
Milvus支持的大多数向量索引类型都使用近似最近邻搜索(ANNS),包括:
- FLAT:FLAT适用于小规模百万级数据集上寻求完全准确和精确的搜索结果的场景。
- IVF_FLAT:IVF_FLAT是基于量化的索引,适用于在准确度和查询速度之间寻求理想平衡的场景。
- IVF_SQ8:IVF_SQ8是基于量化的索引,适用于在磁盘、CPU和GPU内存消耗非常有限的情况下寻求显著减少。
- IVF_PQ:IVF_PQ是基于量化的索引,适用于在不考虑准确度的情况下寻求高查询速度。
- HNSW:HNSW是基于图的索引,适用于对搜索效率有很高要求的场景。
- ANNOY:ANNOY是基于树的索引,适用于追求高召回率的场景。
相似度度量方法
在Milvus中,相似度度量方法用于衡量向量之间的相似性。选择一个合适的距离度量方法可以显著提高分类和聚类性能。根据输入数据的形式,选择特定的相似度度量方法以获得最佳性能。
常用于浮点型嵌入向量的度量方法包括:
- 欧氏距离(L2):该度量方法通常用于计算机视觉(CV)领域。
- 内积(IP):该度量方法通常用于自然语言处理(NLP)领域。
常用于二进制嵌入向量的度量方法包括:
- 汉明距离(Hamming):该度量方法通常用于自然语言处理(NLP)领域。
- Jaccard系数(Jaccard):该度量方法通常用于分子相似性搜索领域。
- Tanimoto系数(Tanimoto):该度量方法通常用于分子相似性搜索领域。
- 超结构(Superstructure):该度量方法通常用于搜索分子的相似超结构。
- 亚结构(Substructure):该度量方法通常用于搜索分子的相似亚结构。
应用范例
Milvus使得在应用程序中添加相似度搜索变得轻松
- 图像相似度搜索:将图像转换为向量,并从大规模数据库中迅速返回最相似的图像
- 视频相似度搜索:将关键帧转换为向量,然后将结果输入到Milvus中,在近乎实时的速度下搜索并推荐数十亿个视频。
- 音频相似度搜索:快速查询大量音频数据,如语音、音乐、音效等,并找出相似的声音。 分子相似度搜索:为指定的分子进行高速相似度搜索、亚结构搜索或超结构搜索。
- 推荐系统:基于用户行为和需求推荐信息或产品。
- 问答系统:交互式数字问答聊天机器人,自动回答用户问题。
- DNA序列分类:通过比较相似的DNA序列,以毫秒级准确地对基因进行分类。
- 文本搜索引擎:通过将关键词与文本数据库进行比较,帮助用户找到他们正在寻找的信息。
Milvus架构
系统分为四个层级
- 访问层:访问层由一组无状态的代理组成,作为系统的前端层和用户的终端点。
- 协调器服务:协调器服务将任务分配给工作节点,充当系统的"大脑"。
- 工作节点:工作节点充当系统的"手臂"和"腿部",是无脑执行者,遵循来自协调器服务的指令,并执行用户触发的DML/DDL命令。
存储:存储是系统的"骨架",负责数据持久化。它包括元数据存储、日志代理和对象存储
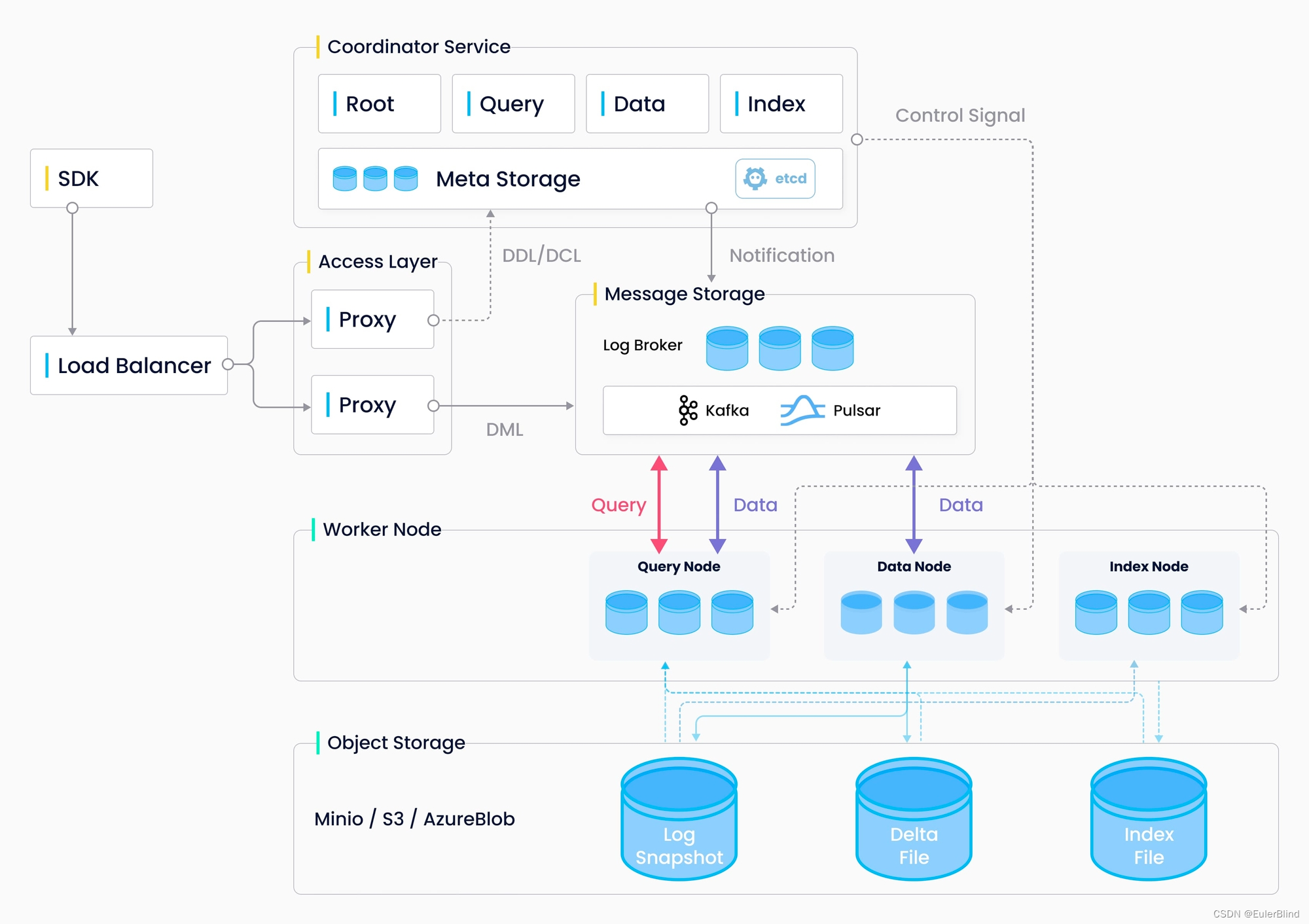
 编辑
编辑
Milvus架构