



Qwen3 完全关闭思考过程(vllm)
根据官方示例,可以通过在提示词里提示模型不输出思考过程,比如提示词直接写【no_thinking】或者【不思考】,在一些场景下都能work,但从结构上来看,其还是会输出 <think></think>的标签。
我们可以通过调整提示词模版的方式,伪装为告诉模型已经完成了思考的形式,进而让模型不输出思考过程。
具体操作方式如下
模型tokenizer配置文件
在你从huggingface下载得到的模型,或者通过unsloth微调得到的模型中,都会找到一个 tokenizer_config.json的配置文件
我们打开这个文件可以看到如下内容,注意这里的 chat_template。
使用如下代码打印一下 chat_template内容
import json
from pathlib import Path
config_path = Path("tokenizer_config.json")
with config_path.open("r") as f:
config_data = json.load(f)
print(config_data.get("chat_template"))
可以看到如下结果:
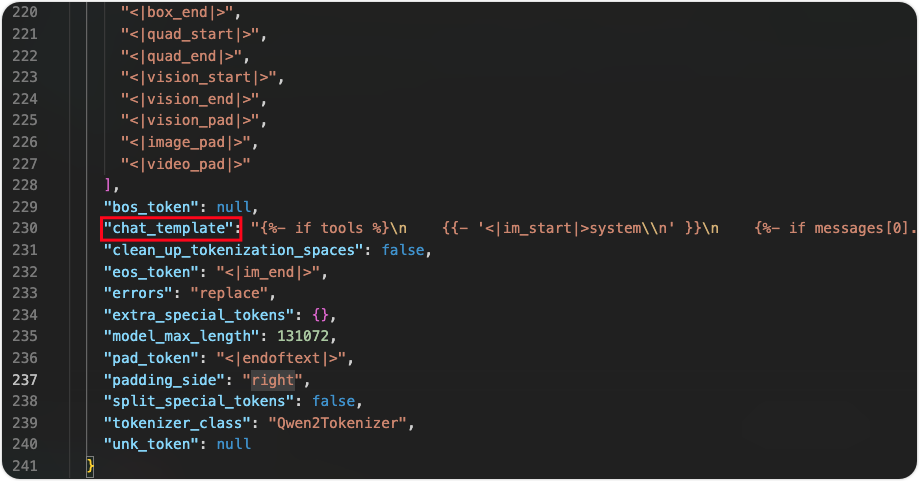
原本内容为如下所示,其内容可以理解为在关闭enable_thinking的情况下,会默认填充 <think>\n\n</think>\n\n数据告诉模型已经完成了思考,继续后面的推理
{%- if enable_thinking is defined and enable_thinking is false %}
{{- '<think>\n\n</think>\n\n' }}
{%- endif %}
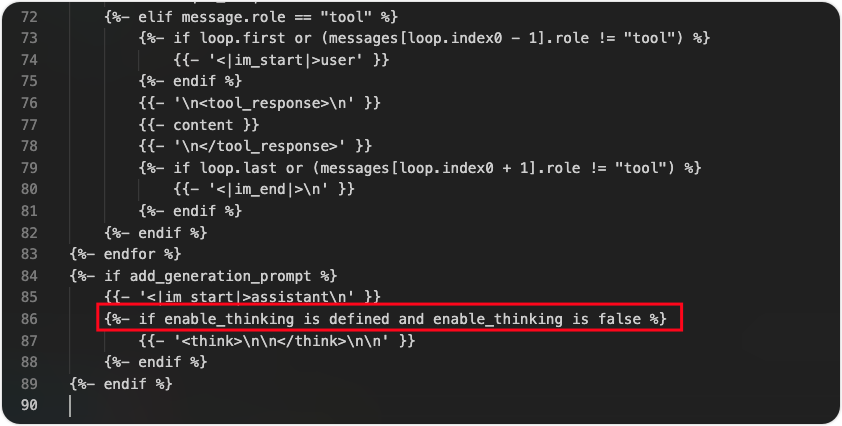
调整模版配置
我们需要将上述内容调整为
{%- if true %}
{{- '<think>\n\n</think>\n\n' }}
{%- endif %}
完整的 chat_template
{"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}\n{%- for message in messages[::-1] %}\n {%- set index = (messages|length - 1) - loop.index0 %}\n {%- if ns.multi_step_tool and message.role == \"user\" and message.content is string and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}\n {%- set ns.multi_step_tool = false %}\n {%- set ns.last_query_index = index %}\n {%- endif %}\n{%- endfor %}\n{%- for message in messages %}\n {%- if message.content is string %}\n {%- set content = message.content %}\n {%- else %}\n {%- set content = '' %}\n {%- endif %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set reasoning_content = '' %}\n {%- if message.reasoning_content is string %}\n {%- set reasoning_content = message.reasoning_content %}\n {%- else %}\n {%- if '</think>' in content %}\n {%- set reasoning_content = content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- set content = content.split('</think>')[-1].lstrip('\\n') %}\n {%- endif %}\n {%- endif %}\n {%- if loop.index0 > ns.last_query_index %}\n {%- if loop.last or (not loop.last and reasoning_content) %}\n {{- '<|im_start|>' + message.role + '\\n<think>\\n' + reasoning_content.strip('\\n') + '\\n</think>\\n\\n' + content.lstrip('\\n') }}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n {%- if true %}\n {{- '<think>\\n\\n</think>\\n\\n' }}\n {%- endif %}\n{%- endif %}",}
修改后的效果:
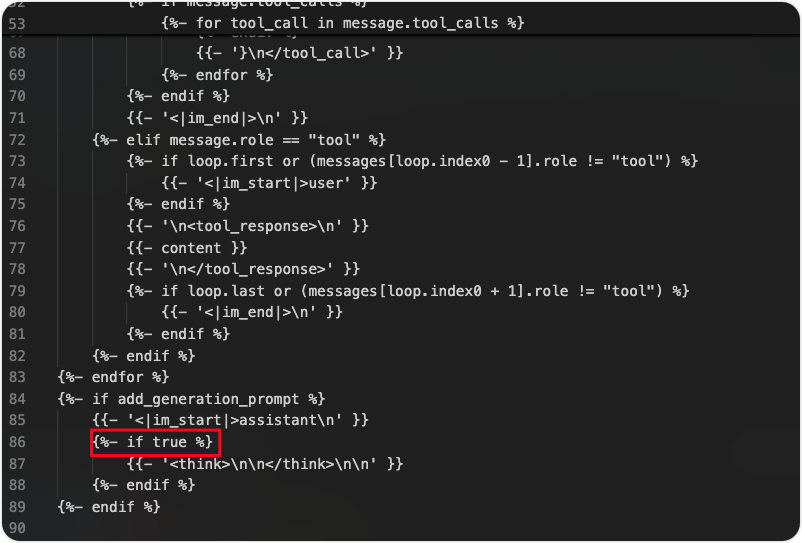
后续启动
完成上述修改后,后续推理部署跟之前vllm推理部署一致即可。
参考:
vllm serve "unsloth/Qwen3-1.7B" \
--port 8060 \
--enable-lora \
--max-lora-rank=64 \
--lora-modules ***=*** \
--max-model-len=15360