



摘要
尽管在台式机GPU上进行的视频目标检测取得了近期的成功,但其架构对于移动设备来说仍然过于沉重。目前还不清楚在非常有限的计算资源下,稀疏特征传播和多帧特征聚合的关键原则是否适用。在本文中,我们提出了一种适用于移动设备视频目标检测的轻量级网络架构。该架构在稀疏关键帧上应用轻量级图像目标检测器。我们设计了一个非常小的网络,名为Light Flow,用于在帧之间建立对应关系。我们还设计了一个流引导的GRU模块,用于在关键帧上有效地聚合特征。对于非关键帧,执行稀疏特征传播。整个网络可以端到端地进行训练。所提出的系统在移动设备上(例如HuaWei Mate 8)以25.6帧每秒的速度实现了60.2%的mAP分数。
Introduction
近年来,使用深度神经网络在目标检测领域取得了显著进展[1]。一般趋势是构建更深、更复杂的目标检测网络[2,3,4,5,6,7,8,9,10,11],以实现更高的准确性。然而,这些在提高准确性方面的进步未必能够使网络在尺寸和速度方面更加高效。在许多实际应用中,如机器人技术、自动驾驶汽车、增强现实和移动电话等领域,目标检测任务需要在计算能力有限的平台上实时进行。
近年来,人们对构建非常小型、低延迟模型的兴趣不断增加,这些模型可以轻松地与移动和嵌入式视觉应用的设计要求相匹配,例如SqueezeNet [12]、MobileNet [13] 和ShuffleNet [14]等。这些结构是通用的,但并非专门为目标检测任务设计。为此,对于静态图像中的目标检测,已经探索了几种小型深度神经网络架构,如YOLO [15]、YOLOv2 [11]、Tiny YOLO [16]、Tiny SSD [17]等。然而,直接将这些检测器应用于视频面临着新的挑战。首先,在所有视频帧上应用深度网络会引入难以承受的计算成本。其次,视频中很少在静止图像中观察到的问题,如运动模糊、视频虚焦、罕见的姿势等,会导致识别精度下降。
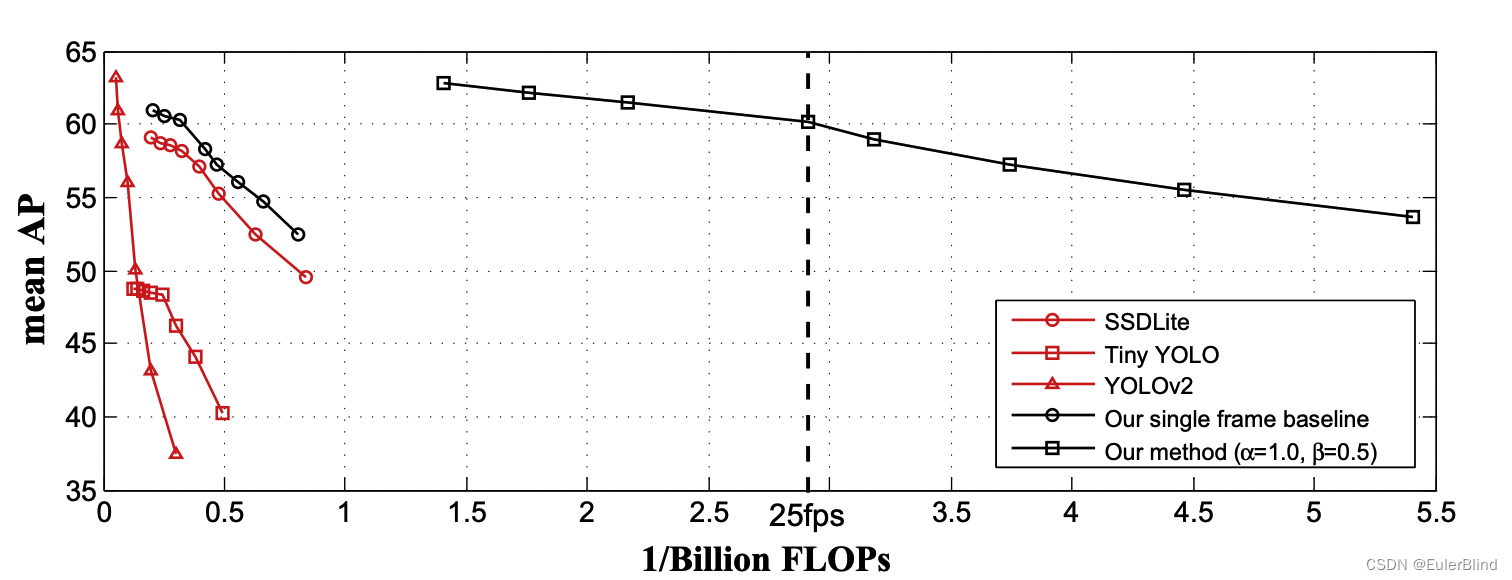

** 图1. 不同轻量级目标检测器的速度-准确性权衡曲线。曲线绘制采用不同的图像分辨率。推理时间是在华为Mate 8的单个2.3GHz Cortex-A72处理器上使用TensorFlow Lite [18]进行评估的。**
为了解决这些问题,目前的最佳实践[19,20,21]在视频中利用时间信息来加速并提高目标检测的准确性。一方面,[19,21]中采用稀疏特征传播,以在大多数帧上节省昂贵的特征计算。这些帧上的特征从稀疏关键帧传播而来,成本较低。另一方面,[20,21]中执行多帧特征聚合,以提高特征质量和检测准确性。
基于这两个原则,最新的研究[21]在台式机GPU上在速度和准确性之间提供了良好的权衡。然而,这种架构对于移动设备来说并不友好。例如,作为特征传播和聚合中关键且常见的组件,光流估计仍然远未达到移动设备实时计算的需求。具有长期依赖性的聚合也受限于移动设备有限的运行时内存。
本论文描述了一种适用于移动设备视频目标检测的轻量级网络架构。主要基于两个原则构建:在大多数非关键帧上传播特征,同时在稀疏关键帧上计算和聚合特征。然而,我们需要考虑速度、尺寸和准确性,仔细重新设计这两个结构以适应移动设备。在所有帧上,我们提出了Light Flow,一个非常小的深度神经网络,用于估计特征流,从而在移动设备上实现即时可用性。在稀疏关键帧上,我们提出了基于流引导的门控循环单元(GRU)特征聚合,这是在内存受限平台上的有效聚合方法。此外,我们还利用轻量级图像目标检测器在关键帧上计算特征,借助先进而高效的技术,如深度可分离卷积[22]和Light-Head R-CNN [23]。
所提出的技术被统一到一个端到端的学习系统中。综合性的实验表明,该模型稳步推进了性能(速度-准确性权衡)的界限,朝着在移动设备上实现高性能视频目标检测的目标迈进。例如,我们在ImageNet VID验证数据集上以每秒25.6帧的速度实现了60.2%的mAP分数,这比先前最好的快速目标检测方法快一个数量级,而准确性相当(参见图1)。据我们所知,我们首次在移动设备上实现了具有相当不错准确性的实时视频目标检测。
近年来,使用深度卷积神经网络(CNN)在静态图像中的目标检测取得了显著进展[1]。最先进的检测器共享类似的网络架构,由两个概念步骤组成。第一步是特征网络,通过完全卷积的主干网络[24,25,26,27,28,29,30,13,14]从输入图像I中提取一组卷积特征图F,表示为Nf eat(I) = F。第二步是检测网络,它根据特征图F生成检测结果y,通过对稀疏目标提案[2,3,4,5,6,7,8,9]或密集滑动窗口[10,15,11,31]执行区域分类和边界框回归,通过一个多分支子网络,即Ndet(F) = y。它是随机初始化的,并与Nf eat一起进行训练。
直接将这些检测器应用于视频目标检测面临两方面的挑战。在速度方面,将单一图像检测器应用于所有视频帧并不高效,因为主干网络Nf eat通常较深且较慢。在准确性方面,视频中很少在静态图像中观察到的问题,如运动模糊、视频虚焦、罕见的姿势,会导致检测准确性下降。
目前的最佳实践[19,20,21]通过稀疏特征传播和多帧特征聚合来利用时间信息,分别解决速度和准确性问题。
稀疏特征传播:由于连续帧之间的内容非常相关,不需要在大多数帧上计算详尽的特征提取。深度特征流[19]提供了一种高效的方式,它仅在稀疏关键帧(例如,每隔10帧)上计算昂贵的特征网络,并将关键帧特征图传播到大多数非关键帧上,从而实现5倍的速度提升,准确性略微下降。
在推理过程中,任何非关键帧i上的特征图都是通过从其前一个关键帧k传播而来的,
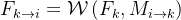
其中,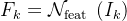 表示关键帧k的特征,而W代表可微分的双线性变形函数。两帧Ii和Ik之间的二维运动场Mi→k通过流网络
表示关键帧k的特征,而W代表可微分的双线性变形函数。两帧Ii和Ik之间的二维运动场Mi→k通过流网络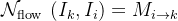 来估计,这比
来估计,这比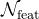 要便宜得多。
要便宜得多。
多帧特征聚合:为了提高检测准确性,流引导的特征聚合(FGFA)[20]从附近的帧中聚合特征图,这些特征图通过估计的光流进行良好的对齐。 在帧i处得到的聚合特征图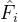 是附近帧特征图的加权平均值,
是附近帧特征图的加权平均值,
![\hat{F}i=\sum{k \in[i-r, i+r]} W_{k \rightarrow i} \odot F_{k \rightarrow i}](https://lsky.elvisiky.com/i/2025/07/01/68636d5d4cf53.png)
其中,⊙ 表示逐元素相乘,权重 Wk→i 是自适应计算的,表示传播的特征图 Fk→i 与帧i处特征图Fi之间的相似性。
Practice for Mobiles
这两个原则,稀疏特征传播和多帧特征聚合,为台式机GPU上的高性能(速度和准确性的权衡)视频目标检测[21]提供了最佳实践。然而,在移动设备上计算能力和运行时内存非常有限。因此,应该探索适用于移动设备的原则。
- 特征提取和聚合仅在稀疏关键帧上进行操作,而大多数非关键帧上执行轻量级特征传播。
- 光流估计是特征传播和聚合的关键。然而,[19,20,21]中使用的光流网络仍然远未满足移动设备上实时处理的需求。具体而言,FlowNet [32] 在相同的输入分辨率下,FLOPs是MobileNet [13]的11.8倍。即使在[19]中使用的最小的FlowNet Inception,FLOPs也多出1.6倍。更加经济的
是非常必要的。
- 特征聚合应该在根据光流对齐的特征图上进行操作。否则,由大物体运动引起的位移会对聚合造成严重误差。聚合中的长期依赖性也受到欢迎,因为可以融合更多的时间信息,以获得更好的特征质量。
- 单一图像检测器的主干网络应尽可能小,因为我们需要它在稀疏关键帧上计算特征。
Model Architecture for Mobiles
基于上述原则,我们为移动设备的视频目标检测设计了一个更小的网络架构。推理流程如图2所示。
给定一个关键帧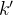 及其前一个关键帧k,首先通过
及其前一个关键帧k,首先通过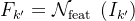 提取特征图,然后将其与其前一个关键帧聚合的特征图
提取特征图,然后将其与其前一个关键帧聚合的特征图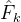 进行聚合,公式为
进行聚合,公式为
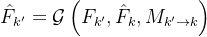
其中G是一个流引导的特征聚合函数。检测网络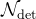 被应用于
被应用于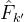 以获取关键帧的检测预测。
以获取关键帧的检测预测。
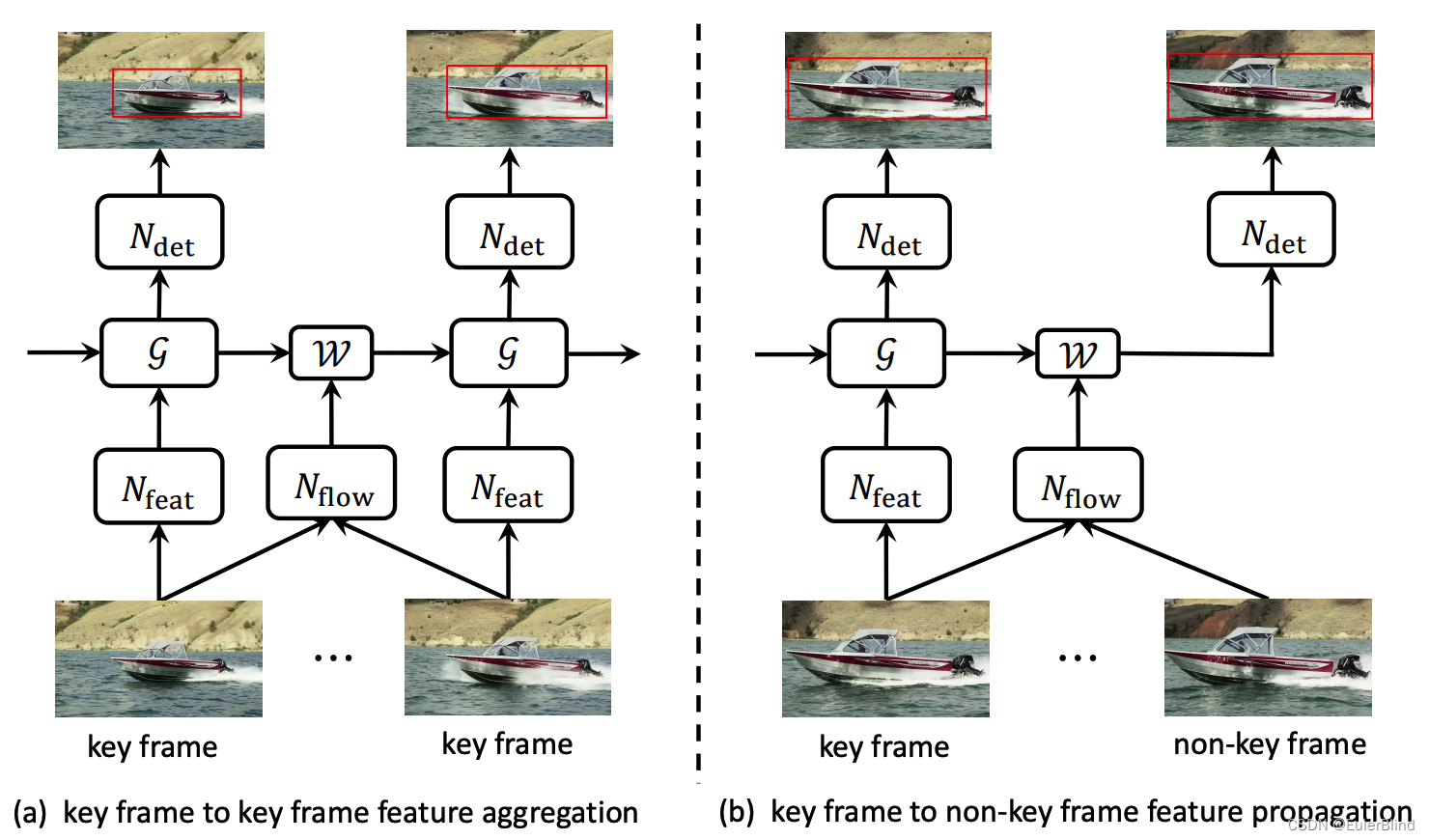
图2. 通过所提出的方法对移动设备进行视频目标检测的示意图。
** 对于非关键帧i,从关键帧k到帧i的特征传播表示为**
其中Fˆ k是关键帧k的聚合特征图,W代表在[19]中也使用的可微分双线性变形函数。然后,检测网络Ndet被应用于Fˆ k→i以获取非关键帧i的检测预测。
接下来,我们将描述两种专为移动设备设计的新技术,包括Light Flow,一种更高效的适用于移动设备的光流网络,以及基于流引导的GRU特征聚合,用于更好地建模长期依赖性,从而提高质量和准确性。